

Fragmented pipelines. Delayed insights. Legacy systems that can’t keep up with real-time demands. For data and infrastructure leaders under pressure to modernise, these aren’t just technical headaches — they’re strategic risks.
As organisations move to cloud-native environments and scale their use of AI, the ability to access, trust, and activate data becomes a non-negotiable part of enterprise success. At the core of this shift is the ETL process: extract, transform, load.
Often treated as a background task, ETL is in fact one of the most critical mechanisms for building modern data pipelines and aligning them to enterprise strategy.
And while some may say it’s outdated, ETL is actually evolving — expanding beyond batch jobs and brittle scripts to support agile, governed, and insight-ready architectures. Understanding where it fits today and how it’s changing is essential for building data strategies that scale with the business.
What Is Extract, Transform, Load (ETL)?
Extract, transform, load is the foundational process that makes enterprise data usable. While the acronym may be decades old, its role in shaping how modern businesses collect, clean, and move information is more important than ever.
ETL is more than just a way to move data. Rather, it’s how enterprises create order from chaos. ETL's whole purpose is taking information from scattered sources and reshaping it into something clean, consistent, and usable. With this process, all that data you generate is now a business asset.
Whether the goal is real-time reporting, AI readiness, or cross-platform visibility, this process is what makes it possible. It connects the operational day-to-day with the strategic decisions that follow.
Extract: Capturing data from the source
Extraction is the first and most variable stage of the ETL process. It involves gathering or pulling data from a whole range of structured and unstructured sources across your organisation. Sources that include databases, APIs, cloud apps, CRMs, IoT sensors, legacy systems, and more.
In enterprise environments, the complexity lies not just in quantity but in consistency. Data often lives across regions, formats, and teams. In fact, most organisations are collecting data from an average of 400 sources. And more than 20 per cent have 1,000 sources feeding BI and analytics systems.
A robust extraction strategy ensures that what gets pulled is both relevant and usable, preserving context and minimising duplication before the transformation begins.
Transform: Shaping and validating data for use
Once data is extracted, it must be transformed to meet the business logic, structure, and quality standards of its destination. This stage includes cleansing, deduplication, standardisation, enrichment, and schema mapping. In regulated industries, it also includes applying rules that ensure data is compliant and auditable.
Transformation is where enterprise data strategies succeed or fail. Done well, it builds trust and usability. When it's done poorly, you end up with problems later in the process. Problems that costs the U.S. around $3 Trillion per year, according to Dr. Thomas C. Redman, President of Data Quality Solutions.
Which is partly why transformation also involves metadata tagging to support governance and observability these days.

Load: Delivering data where it creates value
The final stage is loading the transformed data into a destination system — often a data warehouse, data lake, or lakehouse. And in modern tech stacks, this might also mean you'll be live loading data into analytics engines or machine learning platforms in near real time.
Enterprises must balance latency, scale, and cost when designing the loading process. It’s no longer just about dropping files into storage. Today’s data teams need pipelines that are monitored, versioned, and resilient — ready to scale with demand without sacrificing quality.
Why ETL Still Matters in Enterprise Data Strategy
With all the talk of zero-ETL, ELT, and streaming-first architectures, it’s easy to think ETL’s moment has passed. But for enterprise environments that need to scale, integrate, and govern data with precision, ETL still forms the backbone of strategic delivery. It’s not about holding onto legacy methods. It’s about making sure the foundations are solid before layering on complexity.
When implemented as part of a broader architecture, ETL unlocks speed, visibility, and trust — not just for analytics, but for the entire data lifecycle.
Data pipelines that power decision-making
Data has no value unless it flows. ETL pipelines are what move data from siloed storage into formats and destinations where it can be used to inform decisions. Whether you’re feeding dashboards, activating AI models, or enabling operational reports, you need pipelines that are predictable, performant, and purpose-built.
The right ETL design gives you more than data movement. It gives you confidence that what reaches your analytics layer is accurate, up-to-date, and aligned with business logic. Without that, you’re making decisions on assumptions, not facts.
Governance, trust, and compliance at scale
Enterprises don’t just need data. They need data they can prove, trust, and trace. This is important enough that 71% of organisations have data governance programs in place today, compared to just 60% in 2023.
Because you need to know where data came from, what happened to it, and whether it meets the compliance standards of your industry. ETL is where that chain of control begins.
A well-governed ETL process supports audit trails, metadata capture, data quality checks, and access control. These aren’t optional in regulated environments. They’re what make data usable beyond the next dashboard — especially when it’s being shared across teams, platforms, or countries.
Connecting legacy and modern systems
Very few enterprises get to start from scratch. Most are working within a hybrid mix of legacy systems, cloud platforms, and transitional tools. ETL plays a critical role in bridging those gaps — pulling data from older environments, aligning it to new formats, and delivering it into systems that speak entirely different languages.
Without this connective tissue, digital transformation stalls. ETL gives infrastructure and data leaders a way to modernise without needing to rip and replace everything at once. It makes change manageable, not overwhelming.
How ETL Is Evolving in Modern Business
The shape of ETL has changed. Once defined by overnight batch jobs and brittle scripts, today’s ETL pipelines are shifting toward something faster, more modular, and far more intelligent. This evolution isn’t just about keeping up with tools. It’s about meeting the growing demands of platforms, people, and performance.
For enterprise leaders, the focus is no longer just on getting data from A to B. It’s on how that data moves, how quickly it’s available, and how easily it adapts as systems scale or priorities shift.

From batch loads to real-time ingestion
Traditional ETL was designed around delay. You’d extract, transform, and load once a day, often overnight, in batches that assumed the business could wait. That worked when reporting was monthly and dashboards were static. It doesn’t work now.
Modern ETL has moved to real-time ingestion — streaming data into platforms as it’s created, not after the fact. This enables everything from live dashboards to fraud detection and supply chain optimisation. And it’s not a fringe use case anymore. A Redpanda survey of engineering teams found that 71% of organisations working with streaming data are already adopting it for real-time analytics and AI workloads — with both use cases expected to accelerate over the next 12 to 24 months.
This shift also demands a rethink of how pipelines are triggered, monitored, and maintained. Events, not schedules, are becoming the new default.
Cloud-native architectures and managed services
ETL isn’t something you host in a back room anymore. Most enterprises now run data operations in the cloud, and ETL has followed suit. Instead of building from scratch, teams are adopting cloud-native platforms that offer scalable, managed services built for modern architecture.
Solutions like AWS Glue, Azure Data Factory, and Google Dataflow handle provisioning, orchestration, and scaling without needing dedicated infrastructure teams. That doesn’t mean less control. It means spending less time on low-level configuration and more time building flows that deliver real business outcomes.
AI-led transformation and orchestration
The latest evolution is intelligence. AI is now being embedded into ETL platforms to handle everything from schema detection to anomaly flagging and error recovery. These aren’t just automation scripts. They’re logic layers that improve the reliability and accuracy of the pipeline itself.
Instead of writing manual rules to clean data, platforms can suggest transformations based on patterns. Instead of waiting for a pipeline to break, anomaly detection can intervene before it fails. This is where orchestration gets smarter — not just sequencing tasks, but adapting them in real time.
Done right, intelligent ETL becomes more than infrastructure. It becomes a partner in how your data flows, scales, and delivers value across the business.
Architectural Shifts in Pipeline Development
Not every modern pipeline starts with ETL. As data architectures evolve, new patterns have emerged to meet specific needs around speed, scale, and complexity. Two of the most talked about are ELT and zero-ETL.
Neither is a wholesale replacement for ETL. But both offer alternative approaches that matter, depending on the tools you’re using and the outcomes you need. The goal here isn’t to chase acronyms. It’s to understand which patterns work best for your current state and which are worth planning for.
Zero-ETL: What it is and what it isn’t
Zero-ETL is one of the most misunderstood terms in modern data architecture. It doesn’t mean there are no transformations or pipelines. It means the transformation happens behind the scenes — often built directly into the platform or application where the data is consumed.
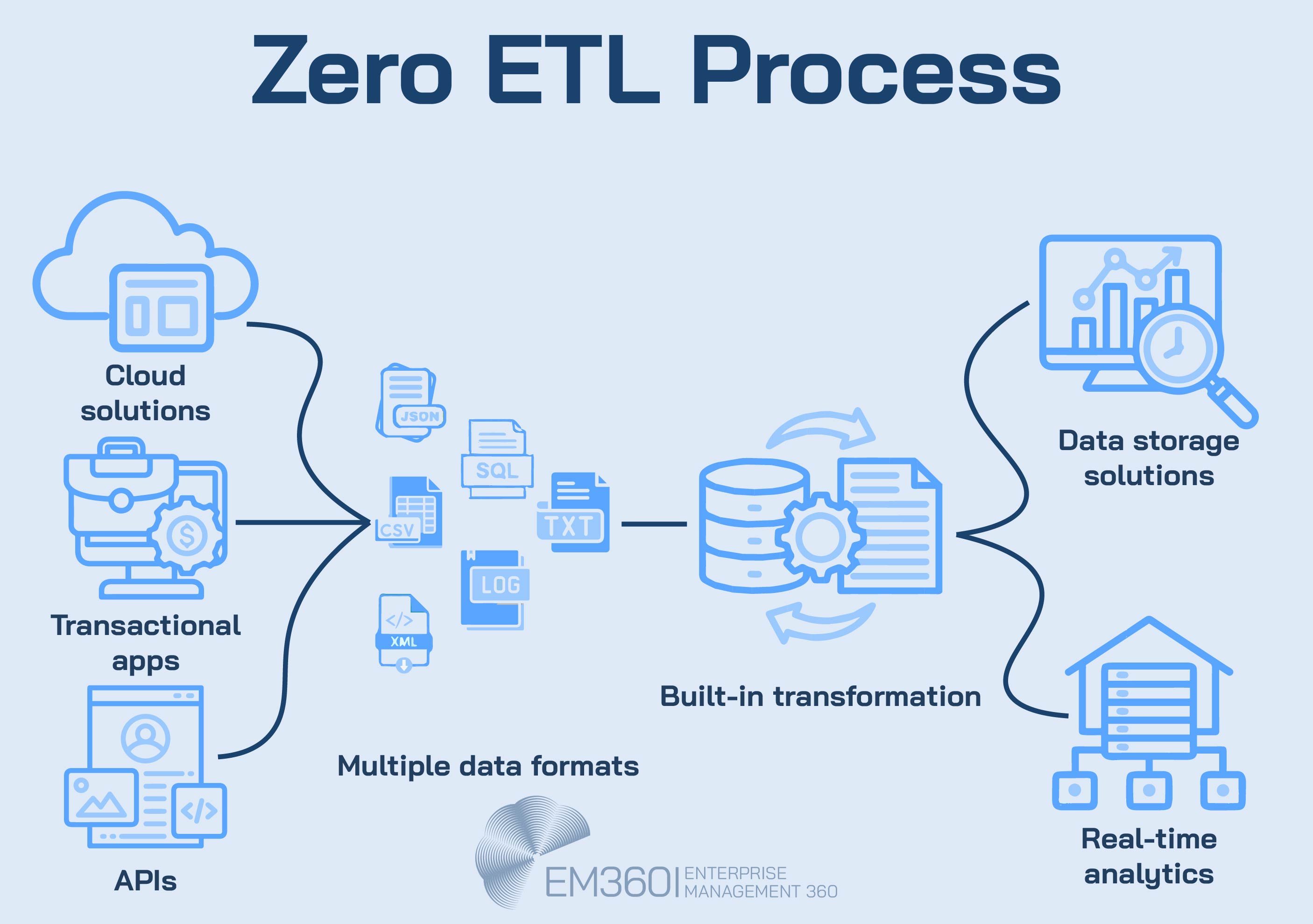
In a zero-ETL pattern, data flows between systems without needing an external process to extract, transform, and load. This is often achieved through tightly integrated services, like moving data directly from an OLTP system to an analytics engine inside the same cloud provider.
This setup reduces latency and simplifies architecture. But it comes with trade-offs. You lose some control over how and when transformations happen. You also need deep alignment between your data sources and platforms, which isn’t always possible in hybrid or multi-cloud environments.
Zero-ETL works best when your systems are already unified — not when you’re trying to stitch together a fragmented stack.
ETL vs ELT: Choosing the right fit
The difference between ETL and ELT comes down to when and where the transformation happens. In ETL, data is transformed before it’s loaded into the destination. In ELT, it’s loaded first, then transformed inside the warehouse or lakehouse using native compute.
ELT has become more common with the rise of cloud-native warehouses like Snowflake, BigQuery, and Redshift. These platforms can scale transformation workloads internally, which shifts the burden away from upstream systems.
But that doesn’t make ETL obsolete. Some transformations — especially those tied to data quality, security, or compliance — are better handled before the data hits the warehouse. ELT works when your destination system is powerful and consistent. ETL is still the better choice when precision, governance, or system interoperability are non-negotiable.
There’s no one-size-fits-all model. The best architectures often use a mix, depending on use case, workload, and platform maturity.
The ETL Tooling Landscape — What to Look For
Choosing the right ETL tool isn’t just a technical decision. It’s a strategic one. The wrong platform can lock you into brittle workflows, inflate operational overheads, and limit visibility. The right one becomes an enabler — helping your team build faster, adapt more easily, and stay in control of how data flows across the organisation.
What matters most is not just feature lists. It’s whether it’s fit for your purposes. Enterprise environments need platforms that can handle complexity without creating chaos.
Key capabilities in modern ETL tools
At the enterprise level, an ETL tool needs to do more than just move data. It should support the full lifecycle of pipeline development, monitoring, and optimisation.
Look for tools that include:
- Connector support for a wide range of data sources and destinations, including things like APIs, cloud apps, databases, and flat files
- Drag-and-drop or low-code interfaces that reduce development time without sacrificing control
- Version control and audit logging to track changes, enable rollback, and support compliance
- Built-in error handling that flags failed runs, retries automatically, and alerts the right people
- Pipeline observability to monitor performance, trace failures, and surface bottlenecks before they impact downstream systems
Enterprise teams also benefit from support for metadata tagging, role-based access, and integration with existing data governance frameworks.
Examples of tools used in enterprise environments
There’s no shortage of ETL tools on the market, but a few consistently show up in large-scale deployments — including those featured in EM360Tech’s partner and solution provider network:
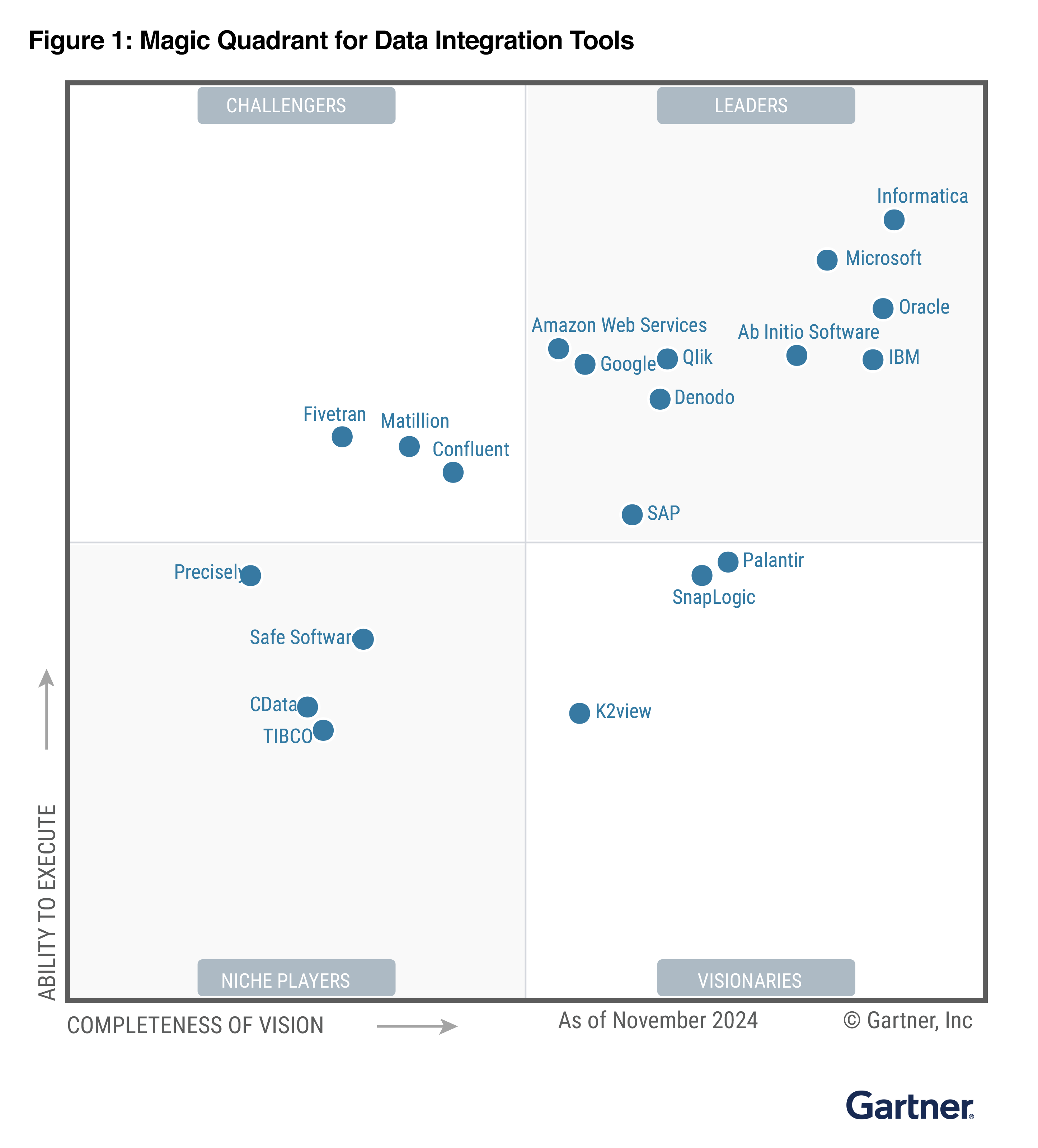
- Informatica: Known for its depth in enterprise data management, with strong support for compliance, lineage, and hybrid environments
- Talend: Offers both open-source and commercial options, with a focus on data quality and trust
- AWS Glue: A fully managed service that works natively within AWS environments and supports both ETL and ELT use cases
- Azure Data Factory: Microsoft’s cloud-native orchestration platform with a wide range of connectors and transformation capabilities
- Google Cloud Dataflow: Ideal for real-time and batch processing with native Apache Beam support
- SnapLogic and Matillion: Strong options for fast development and cloud-native integration, especially in hybrid cloud scenarios
- Fivetran: Known for automated ELT and dynamic schema updates, with over 150 managed connectors
- Integrate.io: A low-code cloud platform designed for fast, secure ETL and change data capture across cloud services
- Rivery: Offers full pipeline orchestration and reverse-ETL functionality for both technical and business teams
- Ascend.io: Focuses on intelligent data automation with declarative pipeline workflows and adaptive resource scaling
- Dataddo: A no-code ETL platform built for fast deployment and scalable integration across analytics stacks
- Astera: Combines data warehouse building and ETL automation in a single no-code environment
Each of these tools approaches the problem differently. They also vary in complexity, maturity and price. But what they all have in common is the ability to scale, simplify, and support modern enterprise architecture.
Migrating From Legacy ETL — Risks and Rewards
Legacy ETL systems weren’t built for today’s demands. They were designed in an era when overnight batch loads were enough, data volumes were manageable, and agility wasn’t the priority it is now. But in modern enterprise environments, those systems often cause more friction than flow.
Migrating off legacy ETL can unlock speed, reliability, and scale as shown in this case study from Visual Flow. But it’s also a high-stakes process — one that requires planning, buy-in, and the right tools to make sure you’re improving performance, not just swapping platforms.
Signs your ETL stack is holding you back
Most legacy ETL tools weren’t built for distributed data, multi-cloud environments, or real-time analytics. They struggle to keep up when new platforms, sources, or business requirements are introduced.
Here are some common warning signs:
- Pipeline breakages increase every time a new data source is added
- Transformation rules are hardcoded and brittle, making changes risky or slow
- Batch windows are too long for business needs, causing delayed insights
- Monitoring and alerting are limited or entirely manual
- Scaling pipelines requires extra infrastructure or manual tuning
- No visibility into how data moves or fails across the stack
These are more than operational frustrations. They affect your ability to respond quickly, stay compliant, and deliver the data trust your teams rely on.
Modernisation strategies and best practices
Successful ETL modernisation isn’t about lifting and shifting. It’s about redesigning pipelines to match how your business works today — and where it’s going next.

Here’s where most enterprise teams start:
- Audit your existing pipelines. Identify which are business-critical, which are redundant, and which need to be rebuilt entirely
- Decouple transformations from infrastructure. Move from brittle scripts to orchestration platforms that support version control, testing, and reusability
- Adopt managed services where possible to reduce operational overhead
- Build for observability. Choose tools that provide insight into performance, error handling, and data quality throughout the flow
- Prioritise modularity. Design your new architecture in smaller, flexible components that are easier to test and scale
- Plan migrations in phases. Focus on high-impact pipelines first, and use parallel runs to validate outputs before decommissioning old systems
The reward isn’t just cleaner pipelines. It’s the ability to move faster, build smarter, and make data decisions you can stand behind.
Common Challenges and Best Practices in ETL
ETL doesn’t usually fail because of one big problem. It fails because of small issues that go unchecked — until they affect the accuracy, reliability, or trustworthiness of your data. It’s why demand for ETL testing services is growing fast, with the market projected to more than double from USD 500 million in 2023 to over USD 1 billion by 2032.
ETL doesn’t usually fail because of one big problem. It fails because of small issues that go unchecked — until they affect the accuracy, reliability, or trustworthiness of your data.
For enterprise teams, the goal is not just building pipelines that work but building pipelines that keep working. This means designing for resilience, visibility, and operational control from day one. Here’s what that looks like in practice.
What goes wrong — and how to avoid it
Even in modern stacks, ETL failures are common. Most aren’t due to inadequate platforms or tools. They happen because pipelines are treated as technical builds instead of long-term assets.
Some of the most frequent issues include:
- Silent data failures that go unnoticed until they show up in a report
- Transformations applied inconsistently, causing discrepancies between teams or regions
- No standardised testing, which means updates can break production pipelines
- Error handling that stops at alerts, without automatic retries or detailed tracebacks
- Lack of version control, making it hard to roll back or audit changes
- Performance degradation over time, especially as volumes and logic increase
The fix isn’t more hands on deck. It’s better process and better visibility.
Best practice here starts with implementing ETL testing frameworks — unit, regression, and schema validation — as standard. Pair that with built-in error recovery, alerting that routes to the right teams, and data quality checks at every stage. These practices don’t slow delivery. They protect it.
ETL in the context of resilient architecture
Resilience isn’t just about uptime. It’s about creating systems that are traceable, compliant, and adaptable when things change.
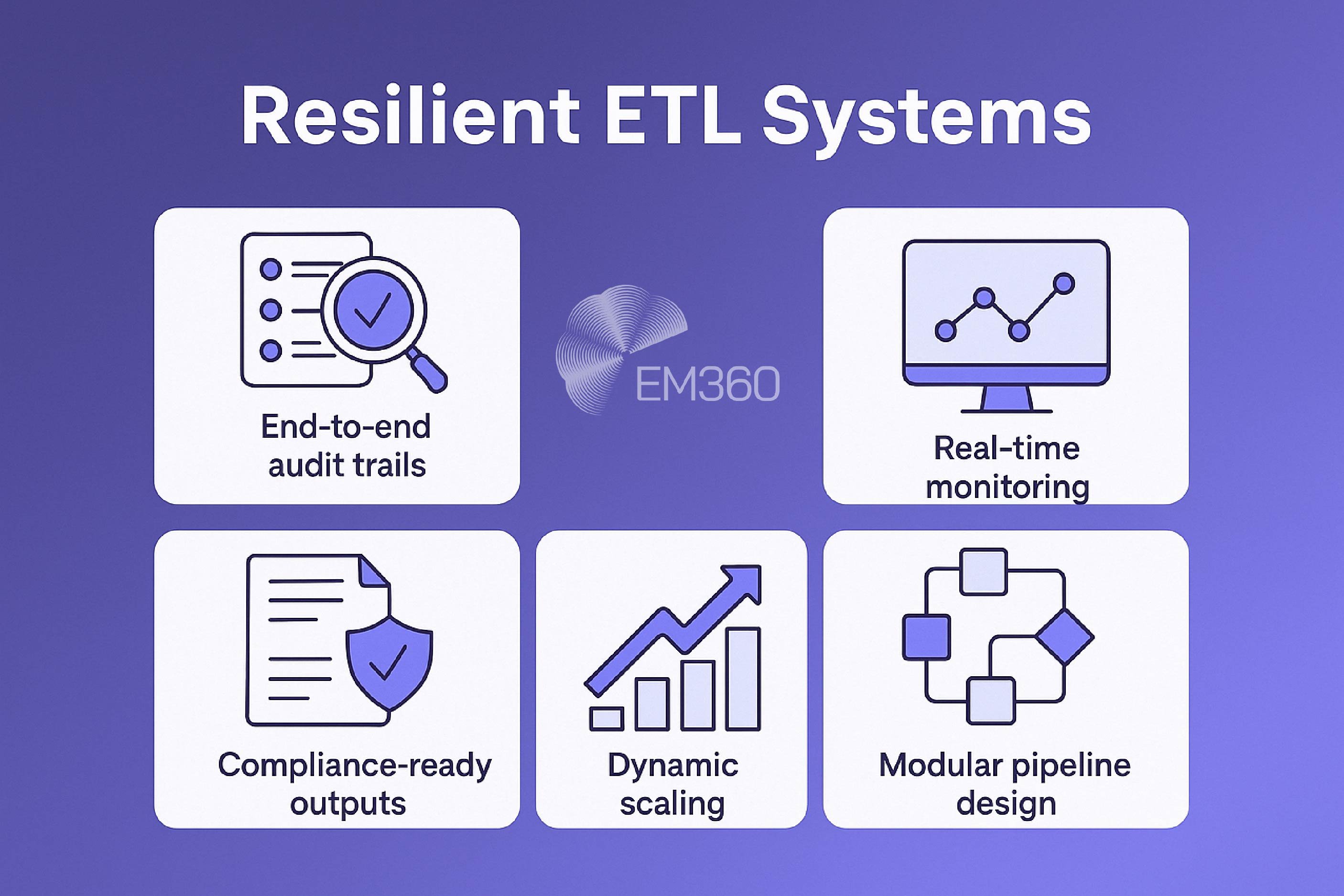
That’s where observability becomes essential. A resilient ETL system includes:
- End-to-end lineage so you can see exactly how data moved and what changed
- Real-time monitoring of pipeline health and throughput
- Compliance-ready outputs, with timestamped logs and traceable transformations
- Dynamic scaling to handle variable loads without degrading performance
- Modular pipeline design that isolates faults and prevents cascading failures
These elements turn ETL from a backend workflow into a core component of your enterprise data architecture. They also make it easier to respond to new requirements without ripping apart what already works.
If your ETL pipelines can’t be trusted, neither can the systems that depend on them. Building for resilience from the start is what keeps data-driven decisions on solid ground.
Where ETL Fits in the Future of Enterprise Data
The way data moves is changing. So is the way teams manage, govern, and scale it. But the need for a clear, controllable, and trustworthy pipeline hasn’t gone away. If anything, it’s become more critical — especially as enterprises aim to deliver faster insights, manage cross-platform sprawl, and stay ahead of shifting compliance requirements.
ETL remains one of the most powerful levers for building an architecture that supports these goals. It's adaptable, not static.
Architecting for insight velocity and scale
The future of enterprise data isn’t just big. It’s fast. Agentic AI and other AI models need real-time access to clean, reliable inputs. Business users expect dashboards that update as quickly as the data itself.
And teams need to run analysis across hybrid environments without waiting on IT to reconfigure pipelines. That’s where modern ETL fits. Not just as a staging layer, but as an accelerator.
By supporting AI-ready pipelines, hybrid architectures, and modular orchestration, ETL helps data teams stay ahead of demand without sacrificing stability. It enables platforms to scale while keeping logic and lineage intact. And it gives infrastructure teams the control they need without slowing down delivery.
This approach isn’t about keeping legacy systems alive. It’s about building for the kind of agility that modern insight demands.
Governance-first thinking in the age of automation
Speed without governance creates risk. As pipelines get faster and more automated, the role of ETL in enforcing policy and oversight becomes even more important.
This is where metadata management and policy-driven orchestration move from nice-to-haves to strategic requirements. Enterprises need to know not just where their data is going but also how it’s been shaped, secured, and approved along the way.
That means baking in validation rules, role-based controls, and audit-ready logs from the start. It also means enabling data stewardship across functions — so governance doesn’t sit only with IT but becomes part of how data flows through the business.
The goal is not just compliant data pipelines. It’s pipelines that can be trusted, explained, and scaled without adding unnecessary friction.
Final Thoughts: ETL Isn't Obsolete, But It Has Grown Up
The goal is not just compliant data pipelines. It’s pipelines that can be trusted, explained, and scaled without adding unnecessary friction.
For something so foundational, ETL doesn’t get much airtime. It’s easy to treat it as a solved problem — a quiet backend function that just moves data around. But that’s not the world we’re working in anymore.
Modern ETL is faster, smarter, and far more strategic than what came before. It’s how organisations are stitching together hybrid platforms, enabling real-time reporting, and preparing their architecture for AI. It’s also where many teams still struggle — with pipelines that are brittle, opaque, or built for business needs that no longer exist.
Getting ETL right is no longer about choosing the right tool. It’s about choosing the right design for how your business uses data now — and how it needs to scale later. That includes automation, observability, and governance from the start. And it means building resilience not as an add-on but as a default.
If you’re rethinking your architecture, planning a migration, or just need to pressure-test your current approach, EM360Tech is here for that. From tooling roundups to peer insights, you’ll find practical, expert-led content to help you move forward with confidence.










Comments ( 0 )